
티스토리 뷰
필자는 캐나다에 살 때, 시원한 바람이 부는 여름, 스타벅스 파티오에 앉아 맥북으로 일을 하는 사람들이 너무 멋있어 보여서 개발자 공부를 시작했다. 그냥 뭔가 구체적이고 대단한 꿈이 아니라 그냥 그게 너무 멋있어 보였다. 개발자가 되기로 마음을 먹고 공부를 시작할 때 여러 유튜브 채널을 구독했는데...
| 유튜버 | 소감 또는 시청 목적 |
| 생활코딩 | Java 기초 영상을 자주 보고(잠이 진짜 잘온다. 그래서 자기전에 틀어놨었다...), 사이트가 따로 있는데 많이 이용했다. |
| 드림코딩 | 외국에서 생활하는 개발자의 삶에 대해 많이 보았다, 개발자가 되고 싶게 열정을 심어주신다. |
| 나도코딩 | 파이썬 기초와 간단한 게임 만들기 프로젝트를 했었다. |
| 홍팍 | SpringBoot 기초를 배웠다. 말하는게 너무 웃기고 재밌어서 시간가는 줄 모르고 공부했다. |
| 코딩애플 | 현재도 잘 보고 있다. 진짜 재밌다. 유용한 정보가 아주 많다. |
그중에서도 홍팍과 코딩애플 이분들은 진짜 재밌다. 툭툭 무심하게 던지는 말투인데 나는 이런 점이 너무나도 재밌었다. 그래서 오늘은!
4주 전에 코딩애플에 INDEX에 관한 영상이 올라왔는데 면접 준비도 해야 하고 좋은 정보라서 여기에 정리하려 한다.
Index
| first_name | age |
| 성치 | 32 |
| 윤발 | 48 |
| 성룡 | 45 |
| 연걸 | 20 |
| 걸륜 | 22 |
위처럼 데이터가 데이터 베이스에 들어가 있다고 생각을 할 때 나이가 20인 행을 찾으려면 SQL문에서는 아래와 같이 찾을 수 있다.
SELECT * FROM T_CHINESE_ACTORS
WHERE AGE = 20;위의 명령문을 실행하면 컴퓨터는 AGE = 20인 행을 찾기 위해 위에서부터 순차적으로 20인 행을 찾는다. 문제는 데이터가 많건 적건 순차적으로 찾는다는 것이다. 데이터가 1억 개가 넘고 AGE = 20이 9000번대에 있다면 컴퓨터는 9000개 이상의 행을 AGE = 20을 찾을 때까지 순차적으로 확인해볼 것이다.
지금이야 컴퓨터가 우리가 시키는 일을 묵묵히 해주지만 chatGPT를 본 필자의 생각으론 미래에 이런 식으로 컴퓨터에게 명령을 한다면 아무래도 짜증을 내면서 INDEX를 설정하라고 잔소리를 할 것 같다... (아니면 이미 짜놨겠지)
Index 이해하기
1부터 100까지의 카드가 있을 때 내가 생각하고 있는 하나의 번호를 상대방에게 맞춰보라고 묻는다면?
상대방: 3
나: 땡
상대방: 70
나: 땡
➡이런 식으로 맞춰보려 한다면 재수가 없는 경우엔 100번째에 맞출 수도 있다.
하지만 아래의 방법을 쓴다면 더 쉽다.
상대방: 50 업?
나: 웅
상대방: 75 업?
나: 노, 다운
위의 방법을 데이터에도 적용한다면 반씩 빠르게 소거하며 우리가 원하는 데이터를 빠르게 찾아낼 수 있다.
문제는 기준점이 필요하기 때문에 위의 표를 아래와 같이 순서대로 정렬(AGE 만)을 해야 한다.
| age |
| 20 |
| 22 |
| 32 |
| 45 |
| 48 |
이렇게 정렬을 해둔 age 컬럼사본을 index라고 한다.
데이터 베이스에서의 Index
데이터 베이스에서의 index는 트리 형태를 띠고 있다.

위의 그림에 따라 5라는 자료를 찾기 위해서는 4보다 큰지 6보다 작은지만 물어본다면 쉽게 찾을 수 있다. (단 2번의 질문)
데이터 베이스에서 위와 같이 배치해 둔 트리를 전문용어로 Binary Search Tree라고 부른다.
위 트리의 성능을 좀 더 강화할 수 있는데 노드마다 숫자를 두개에서 세개씩 넣어버리는 방법이다.
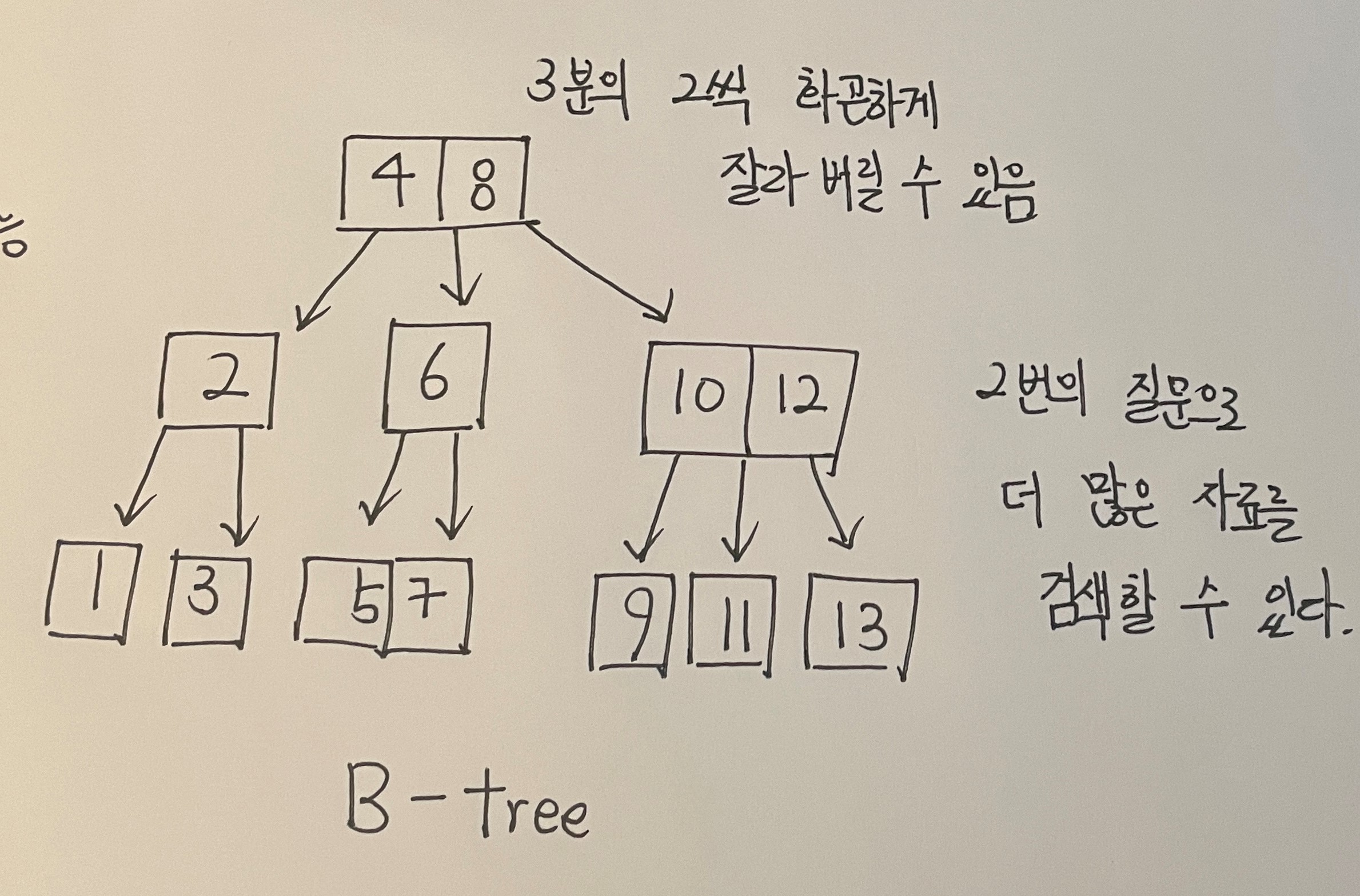
B-tree 구조는 3분의 2씩 화끈하게 잘라버릴 수 있고 단 2번의 질문으로 더 많은 양의 자료를 검색할 수 있다.
위 트리의 성능을 좀 더 강화 할 수 있는데 그것은 바로 아래의 B+tree이다.
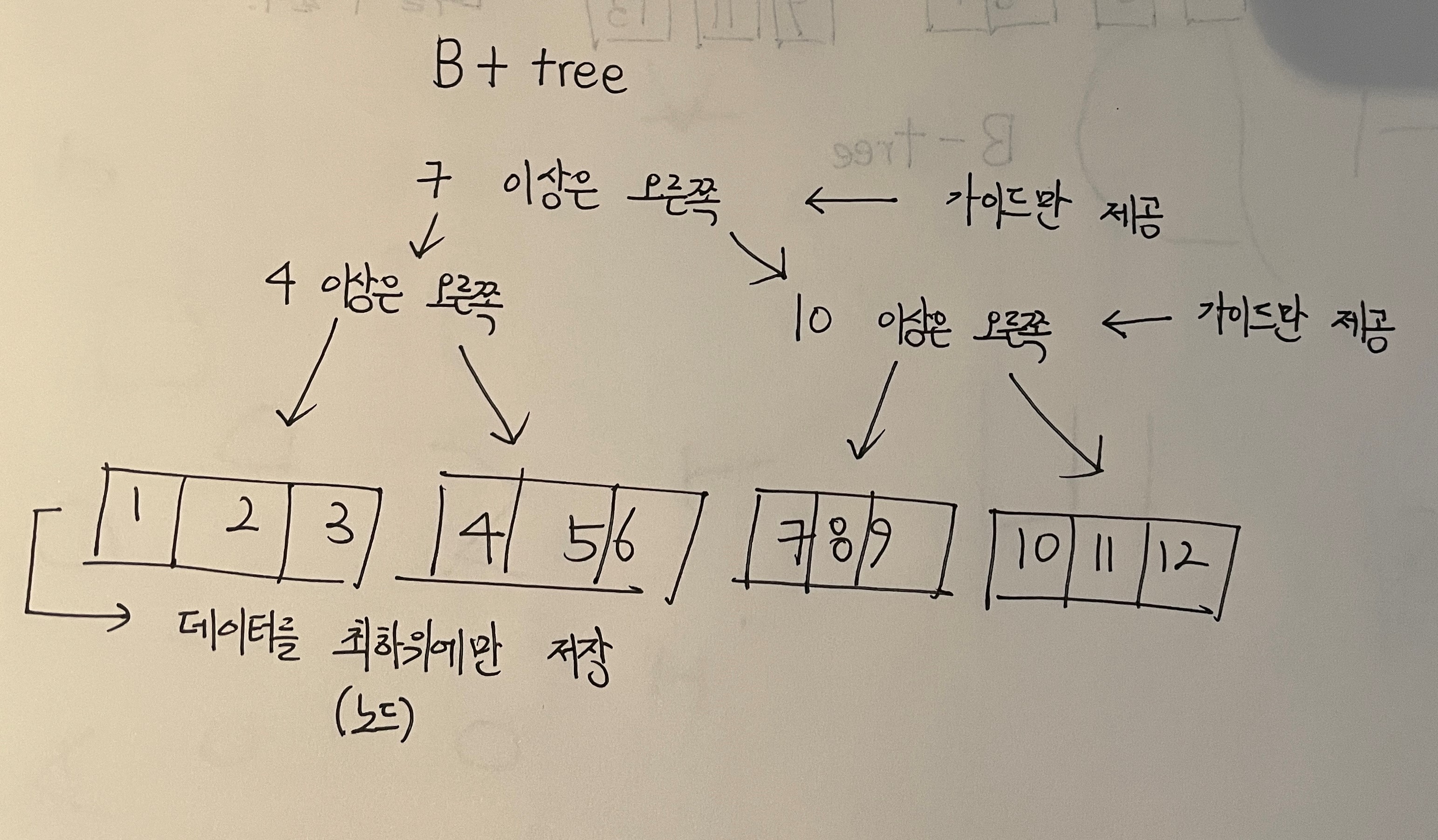
정리
"컴터님 AGE = 20인 행을 찾아와 주세요"
➡ index가 없는 경우
- 모든 행을 다 뒤짐
➡ index가 있는 경우
- index에서 AGE = 20을 빠르게 찾음
- index와 연결된 원래 테이블 행을 가져옴
index의 단점
- 컬럼을 복사해서 인덱스를 만들기 때문에 DB 용량이 늘어난다. (검색 작업이 필요없는 컬럼에는 index가 필요 없음)
- 기존 컬럼의 데이터를 삽입, 수정, 삭제할 때 index에도 반영해야 하는 번거로움 ➡ 성능 하락 (크게 신경은 안 써도 됨)
참고로 Primary key(id)는 index가 필요 없음. Primary key(id) 자체를 Clustered index라고 부른다.
출처
코딩애플
https://www.youtube.com/@codingapple
코딩애플
www.youtube.com
'Computer Science' 카테고리의 다른 글
| [CS] 컴퓨터의 구성 (0) | 2023.02.22 |
|---|
- Total
- Today
- Yesterday
- function
- 동기코딩
- method
- 타입스크립트
- if문
- javascript
- Type
- em
- 프로그래머스
- 자바스크립트
- 타입 좁히기
- Margin
- html table
- Object
- html
- Array
- 파이썬
- CSS 포지션
- 실수
- 함수
- HTML 기본
- 반복문
- css position
- 메서드
- CSS
- Python
- padding
- Typescript
- for문
- 객체
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |